
Lumen’s Quiet Veto on DMCA Abuse Investigations
Harvard's takedown archive won't explain why my project is "not aligned" with its mission.

What happens when the internet’s premier archive of DMCA claims declines to help investigate censorship and fraud?

Just over a week ago on a February afternoon, I found myself browsing yet another set of odd-looking DMCA notices when I decided to ask Lumen Database for an API key to access their database.
An API key is essentially a researcher login for software; a credential that lets you automatically query large volumes of data instead of clicking through individual records by hand. In my email, I described a straightforward project: examine how one prolific sender of DMCA and related takedown notices might be using copyright law to target lawful reporting and public‑interest speech.
The outputs, I wrote, would be “public, written journalism and analysis,” and I signed it with my name and publication.
Lumen replied the following morning that my “plans and outputs do not align with Lumen’s current goals and mission” and declined access, then ignored a follow‑up request to explain that contradiction.
Lumen’s official account follows me on Twitter, which makes it hard to argue this was an anonymous or context‑free request from a stranger they knew nothing about.
Because Lumen says it exists to document the censorship machinery that operates through legal threats, walling off deeper access to that machinery isn’t a neutral administrative act.
It’s a choice with real consequences for accountability.
The transparency project that gets to say no
Lumen is a project of Harvard’s Berkman Klein Center, which describes it as collecting and studying online content‑removal requests “providing transparency and supporting analysis of the Web’s takedown ‘ecology.’”
UNESCO’s profile summarizes Lumen’s purpose as promoting transparency about “who sends and receives these notices, why, and what online content they refer to,” and facilitating research on “both legitimate and questionable” complaints. The database is populated by voluntary contributions from companies such as Google, Twitter, and YouTube.
On its Researchers page and in its API terms, Lumen tells the world that it generally issues researcher credentials to people or non‑profits planning “journalistic, academic, or legislative & regulatory policy‑focused public written research outputs,” explicitly naming news articles, journal pieces, and white papers as acceptable outputs.
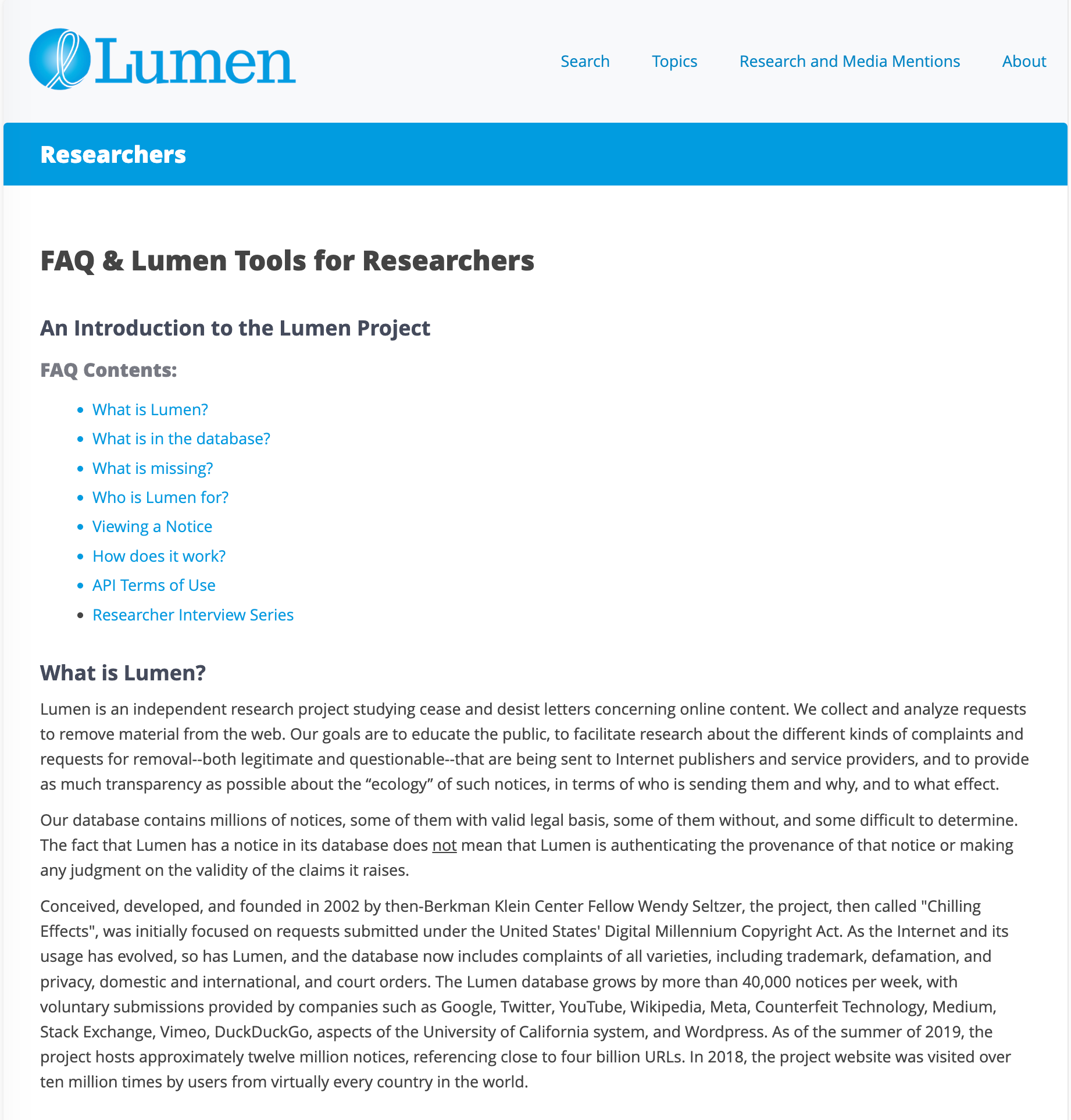
Independent researchers are explicitly eligible; the terms define a “Researcher” as anyone using the API for such a purpose, whether institutionally affiliated or not.
The same API terms contain a sweeping escape hatch: “Lumen reserves the right to deny or refuse to grant API access for any reason.” There is no described public appeal process in those terms, no obligation to provide a reason, and no published statistics on who is refused.

Lumen did not respond to my follow‑up email explaining I was writing a story about their organization and asking for comment on how my “described plans and outputs do not align with Lumen’s current goals and mission.”
A textbook fit (on paper)
Put Lumen’s public description next to the project it declined and the alignment appears perfect. Lumen says it wants to document the “ecology” of online removal requests: who sends them, why, and to what effect.
I proposed to:
Map the takedown activity of one frequent submitter over time and across platforms and targets
Evaluate how often that entity’s notices appear overbroad, retaliatory, or aimed at lawful reporting and commentary
Examine which topics, individuals, or organizations are most frequently targeted, and whether notices cluster around particular events or critical coverage
The outputs would be public journalism and analysis, with clear methodological notes about how Lumen data were used and my expressed willingness to follow any preferred citation or data‑handling practices.

Those are precisely the kinds of “journalistic” outputs Lumen cites when defining acceptable research purposes in its API terms. I was able to find various external descriptions of Lumen reinforcing that same expectation.
Bellingcat’s online investigations toolkit describes Lumen as a Harvard‑affiliated research database of “legal complaints and content‑removal requests (e.g., DMCA, defamation, court orders)” and explains how researchers can use it as part of large‑scale investigations. Based on Bellingcat’s understanding and Lumen’s own docs, their API access is meant for just the sort of systematic pattern analysis that my proposed work needed.
Lumen’s refusal, then, was not simply a matter of limited resources or some ill‑fitting use case. On the public record, my project’s aims sit squarely inside the organization’s announced remit.
The gap lies in how Lumen currently defines its “goals and mission” in practice, and who exactly is allowed to test the limits of abusive notice‑sending.
When a transparency archive narrows the aperture
This is not the first time observers have questioned whether Lumen’s operational choices match its transparency rhetoric.
In 2020, TorrentFreak reported that Lumen had removed precise URLs from public copies of DMCA notices, replacing them with domain‑level information and requiring users to enter an email address to receive a single‑use link to view full details. The outlet, which called Lumen “an essential tool for researchers and reporters interested in the cease‑and‑desist landscape,” warned that “reduced access will probably be disappointing for some,” and noted that the new hoops “place obstacles in the way of legitimate research and accountability.”
Lumen project manager Adam Holland told TorrentFreak the changes were meant to keep Lumen a “vibrant and valuable feature…for research, journalism, and public awareness around takedown requests” while addressing concerns about people using the database as a directory of infringing links and reducing staff workload. In his account, the research community’s experience would remain “in no way” compromised.
Even some copyright‑enforcement professionals were uneasy. A representative from an anti‑piracy company told TorrentFreak that while his clients welcomed less visibility for infringing URLs, he shared “the concerns of those who may feel that this places obstacles in the way of legitimate research and accountability.”
A pattern appears:
Lumen and its institutional home present the project as a neutral infrastructure for transparency and research on legal threats to speech.
To manage internal workload and external sensitivities, they narrow public access and route serious work through privileged channels such as researcher logins and API keys.
Those privileged channels are themselves controlled by opaque, discretionary access decisions with no external oversight.
An unexplained denial of API access to a journalist scrutinizing one particularly prolific takedown sender is a sharper expression of the same dynamic.
Additional denials may have occurred of which the public is not yet aware.
The quiet power to shape which abuses are visible
The stakes are concrete. Fraudulent and retaliatory takedown campaigns have become a quiet but effective tool for reputation management and suppression of critical reporting under the banner of the DMCA.
A 2024 analysis by Tax Policy Associates titled “The epidemic of fraudulent DMCA takedowns” described an “invisible campaign to censor the internet” through bogus copyright notices, especially those sent to Google, aimed at burying investigative or critical articles in search results. Drawing on Lumen data, the author detailed networks of shell companies and fake media entities submitting near‑identical DMCA complaints to remove unflattering coverage of tax disputes, political figures, and alleged misconduct.
Journalist Mike Masnick, writing at Techdirt, has likewise documented “fake entities…still abusing the DMCA takedown process” to scrub factual reporting, using Lumen entries to trace clusters of notices tied to a reputation‑laundering operation built around a string of invented “Media Corporation” brands. Another analysis at Walled Culture showed how backdated copies of articles are used to generate fraudulent notices that convince platforms to remove the original investigative pieces.
These investigations make one thing clear: Lumen’s archive is not just a passive record. It is often the only way to spot repetition and coordination across platforms that individual transparency reports, or scattered notices, will never reveal.
Other observers treat Lumen as central infrastructure. The Canadian think tank CIGI, in its report “Weaponizing Privacy and Copyright Law for Censorship”, points to the role of databases like Lumen in tracking censorship‑adjacent use of copyright and privacy law.
Google itself, in its About Lumen documentation, explains that it contributes certain legal removal requests to the project, and describes Lumen as a Harvard‑based initiative that “collects and analyzes legal complaints and requests for removal of online materials.” Google explicitly links that sharing to goals of transparency and public oversight of content removal.
That privileged position comes with quiet, unreviewable power. By controlling scalable access to the underlying data, Lumen can determine which journalists and researchers can efficiently test powerful actors’ use of copyright, defamation, or court orders to scrub the public record.
Lumen’s own notice‑information page explains that some information is restricted to researchers and that fields, including URLs, may appear as redacted for the general public. After the 2020 changes, full notice details are often available only through email‑gated single‑use links. The web interface allows viewing one complete notice at a time and running basic keyword searches, but trying to map a prolific sender’s behavior that way is effectively research via pipette.
From the public record, the structure looks like this:
[ Notice Senders ]
│
│ (DMCA, defamation, court orders, other takedown requests)
▼
[ Platforms / Intermediaries ]
│
│ (Some or all notices forwarded for "transparency" [CYA])
▼
[ Lumen Database ]
│
│ Public web interface
│ (Single-notice, email-gated access for full details)
│
└───► [ API Access ]
│
│ (Sranted or denied at Lumen's discretion)
▼
[ Researchers / Journalists ]When those gatekeepers quietly decline, without explanation, the chill is subtle but real. The path of least resistance is to focus on aggregated trends or generic “DMCA abuse,” not on how a particular company, law firm, or political actor is exploiting the system.
Lumen’s silence on my request for clarification leaves open uncomfortable questions that belong in the public record.
Why this should matter to policymakers and platforms
For policymakers and platforms that tout transparency as a partial answer to overbroad content removal, Lumen’s access posture raises several uncomfortable implications.
First, if governments and companies point to Lumen as proof of accountability while Lumen quietly controls who can conduct serious analysis, transparency becomes a talking point rather than a practice. UNESCO’s treatment of Lumen in its World Trends in Freedom of Expression materials underscores its perceived role as a public good in the media freedom ecosystem. That status is undermined if its most powerful analytical tools are selectively withheld from independent scrutiny.
Second, platforms like Google that highlight their participation in Lumen in transparency materials should be pressed on whether they are comfortable with an arrangement in which the primary public archive of their legal notices is not meaningfully accountable to the wider research and journalism community. If Lumen’s access decisions systematically or even sporadically shield high‑volume senders from investigation, platforms are implicated in that outcome.
Third, legislators considering reforms to notice‑and‑takedown regimes should recognize that “transparency” is not binary. A database can exist, be technically public, and be cited in policy debates while still being organized in ways that frustrate the very investigations it is meant to enable. Access design is policy.
Finally, there is a deeper structural question: should a single, privately governed institution occupy such a central position in documenting legal threats to online speech? Work on open data and research access has highlighted how opaque refusals can undercut the public interest even when framed as responsible stewardship. Lumen’s trajectory and practices deserve the same level of critical scrutiny that it has so usefully allowed researchers to apply to everyone else.
What is already clear is this: a project widely treated as the public’s telescope into the world of legal takedown threats is also the gatekeeper to that telescope’s highest‑powered lens. When that gatekeeper quietly tells a researcher her plans no longer fit its mission, and declines to explain why, the story isn’t about a single denied API key, or that researcher’s annoyance at the denial.
It’s about who gets to study censorship, and on whose terms.